
https://tinystash.undef.im/il/5PWwiVA4vdWNdini1PTEnrbqwn53uv22XP2BDjisdPs5TYSW4FVqvs2UCjku2A7RVRAKuU2P4tHHE7hFkqC86yhY.jpeg
Три года мы расследовали это и наконец нам удалось это доказать: те же ГРУшники из вч 29155, что отравили Скрипаля, калечат американских дипломатов по всему миру секретным оружием:
Разгадка «гаванского синдрома»: как ГРУ калечит американских дипломатов секретным оружием
https://theins.ru/politika/270420


https://tinystash.undef.im/il/3xzWJ6vcRwRSmQeZeKn8zLVh5Yc76aFv2tt7fAxgSsWgYQzTud56hWxQcFGJV52S5G4sCQTLkWM7G7bQ5RzXJJ8u.txt
Пол Крэйг Робертс, Институт политической экономии
#MN60ZP
(0)
/ @anonymous / 1623 дня назад



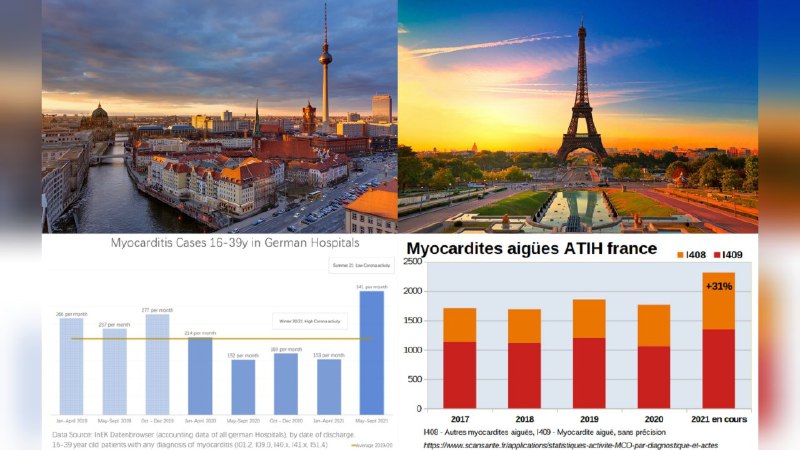
https://tinystash.undef.im/il/48pEWPcjNP6t4LE6YLqkuuZF48hPXXySi3HS7YYn6NK7w3KFqVhi6V9Pdbwf2ZX4b1LiCPgZ2rxuiUzc9ZDD2bMB.txt
⸰
Новое научное исследование, проведенное доктором Питером Маккаллоу и другими ведущими учеными, пришло к выводу,
что вакцины против Covid-19 повреждают врожденную иммунную систему
#KBIU1C
(0)
/ @anonymous / 1627 дней назад

Привился экспериментальной вакциной и умер – никто страховку платить не будет
https://russtrat.ru/analytics/29-yanvarya-2022-0010-8366
#876QLG
(0)
/ @anonymous / 1628 дней назад
#52L1DD
(0)
/ @anonymous / 1637 дней назад
Будущее нейротехнологий: гибридный человек
перевод: https://tinystash.undef.im/il/HoA7VCqw3DVF6aSG7EBQBKHiVk1t5n5YBKmyGryDQ1srKsmyBzbxkot2q9w9wHeMDeWtYcxH2jJwGoo9Qfcq7Un.txt
оригинал: https://beppegrillo.it/il-futuro-della-neurotecnologia-luomo-ibrido/
#5OTGAS
(0)
/ @anonymous / 1637 дней назад

Цоперайт © 2010-2016 @stiletto.