Допустим у меня есть бэкап в виде почасовых дампов жирных табличек базы данных, то есть файлики которые различаются только хвостом. Придумала ли компьютерная наука оптимальный способ сжатия для таких случаев? (чтобы размер архива был хотя бы равен размеру одного из файлов)
УНЯНЯ. У нас есть немножечко инфы
об этом пользователе. Мы знаем, что он понаписал,
порекомендовал и даже и то и другое сразу.
А ещё у нас есть RSS.

>>> import numpy as np
>>> x = np.array([1,2,3])
>>> y = x[:]
>>> x[0] = -1
>>> y
array([-1, 2, 3])
>>>
#3R31EL
(9)
/ @mugiseyebrows / 2087 дней назад
blyad ebuchaya ubunta, stavish 18.04 s fleshki (len kachat novuyu) i sosesh s
`Updating from such a repository can't be done securely, and is therefore disabled by default` i nihuya iz `https://askubuntu.com/questions/732985/force-update-from-unsigned-repository` ne rabotaet blyad, ebanoe vsyo suka dermo zhopa her
#0B8HM2
(7)
/ @mugiseyebrows / 2099 дней назад
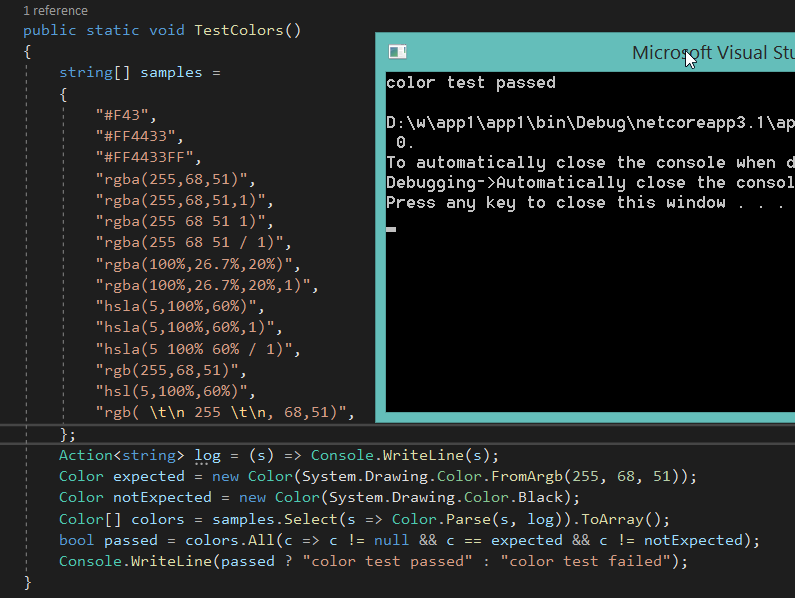
Сегодня парсер цветов
https://mugiseyebrows.github.io/img/mugiml22.png
#AP3TQJ
(4)
/ @mugiseyebrows / 2100 дней назад
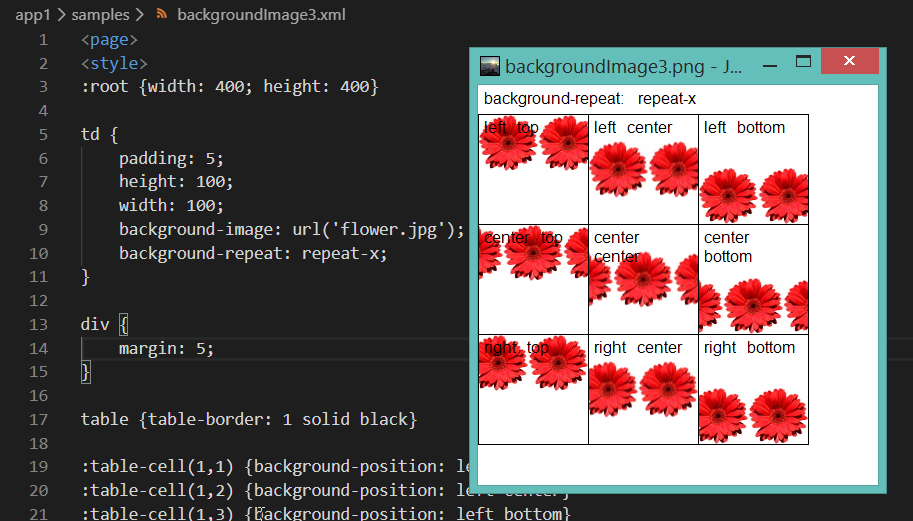
Дайен, сегодня я background-image
https://mugiseyebrows.github.io/img/mugiml21.png
#BENDZG
(2)
/ @mugiseyebrows / 2103 дня назад
бнвач - помогач
как мне заебенить диаграмку, типа есть градуировочка по некоторому признаку: 10 - пук 20 - кек 30 - чух
и два значения этого признака: 13 - нормис, 18 - аутисты
похуй на чём, в экселе, в matplotlib или онлаен-сэрвисе
бонуспоинтс если можно гауссиану нарисовать вместо значения
#L0PKHA
(19)
/ @mugiseyebrows / 2104 дня назад
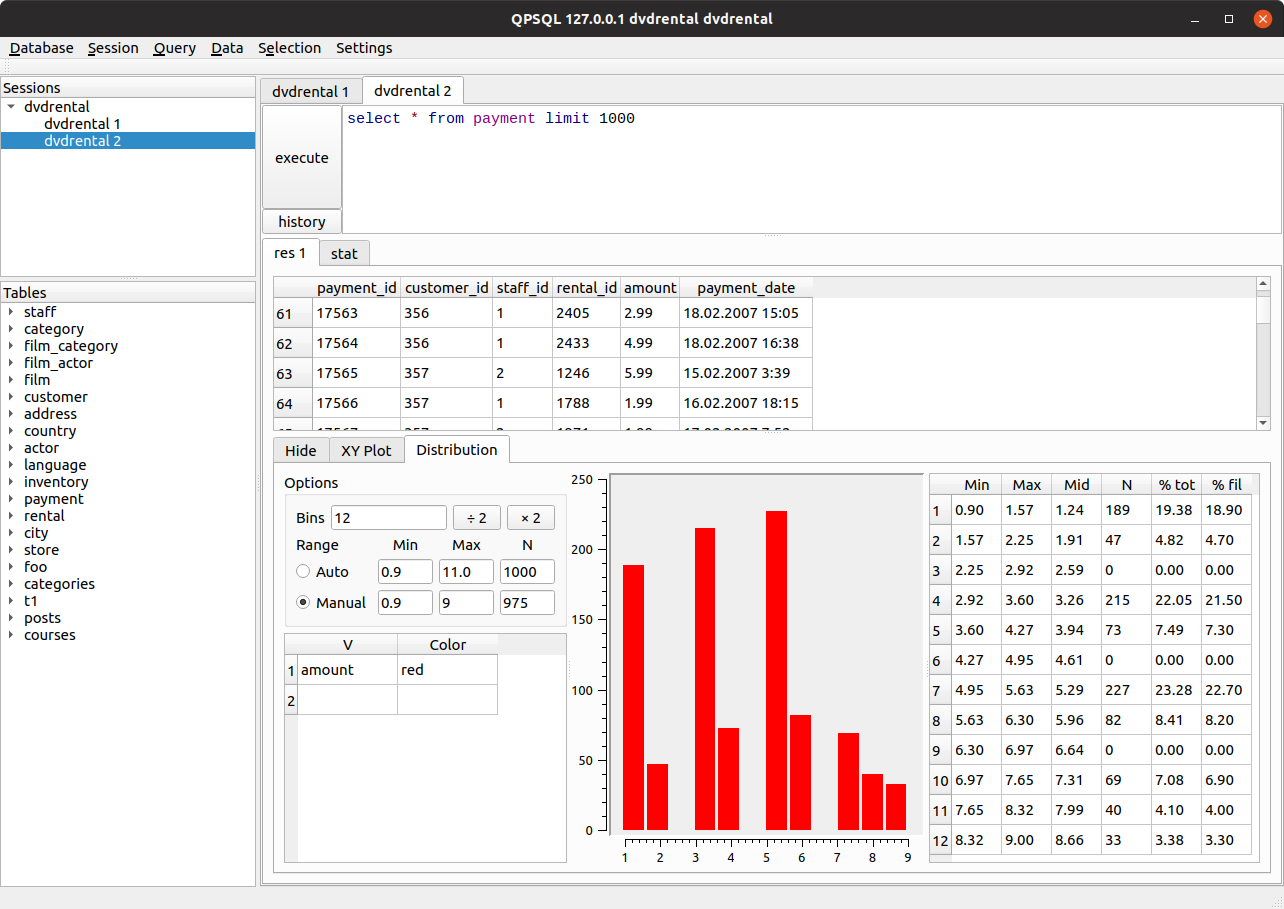
Сегодня я таблицу распределения в своём эскьюэл-клиенте
https://mugiseyebrows.github.io/img/mugi-query-hist-table.png
#E1RCK4
(0)
/ @mugiseyebrows / 2105 дней назад
тфв гуглишь пузырьковую сортировку
тфв первая ссылка с __очевидно__ неправильным кодом
#HV2LY8
(1)
/ @mugiseyebrows / 2107 дней назад
Сижу башку ломаю хули число в кьют-модель не приходит хотя в консоль пукается а тама `numpy.float64` оказывается вместо `float` ну заебись, чо привести нельзя было?
#SXZ3DX
(1)
/ @mugiseyebrows / 2108 дней назад
Пердолькаю питоны в редакторе spyder и примерно раз в час он закидывает меня окнами "аутокомплит больше не будет работать сохраните выйдете войдите". Как же удобно ёб твою мать.
#5HRC6Q
(20)
/ @mugiseyebrows / 2109 дней назад
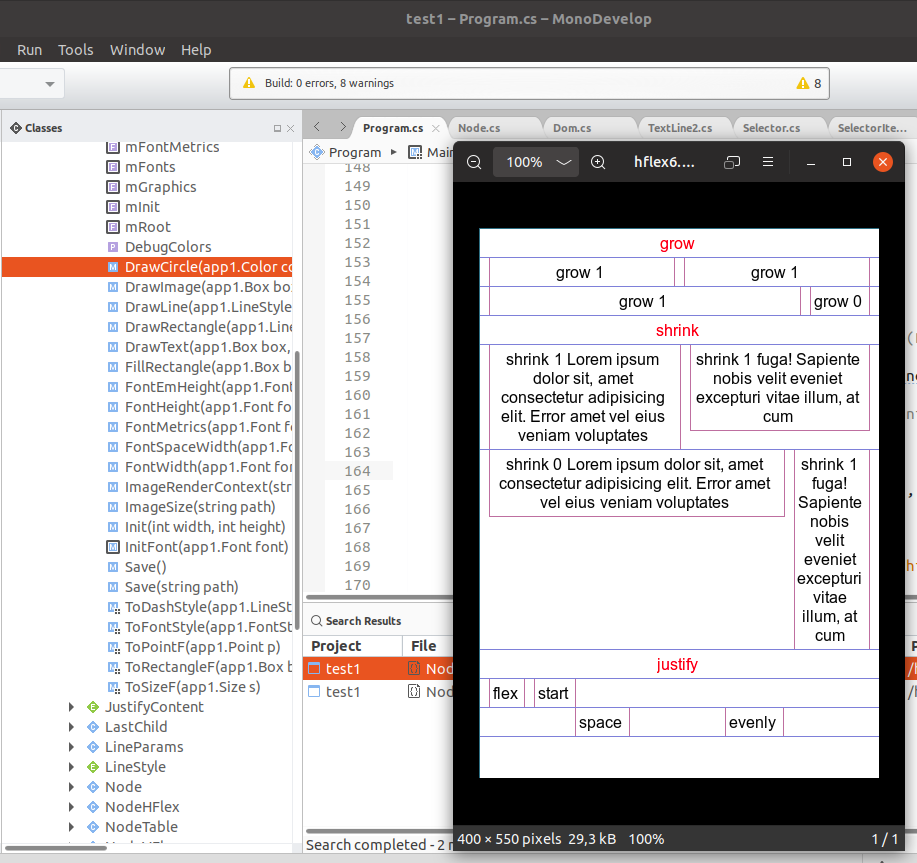
https://mugiseyebrows.github.io/img/mugiml20.png
Сегодня я сконпелюнькал рендерялку под прыщами. Ебаться почти не пришлось, создал проект в монодевелоп, скопировал файлики, подтыкнул отвалившееся, скачал необходимые пакетики из нагета. Пробелы перекорёжило. На десктопе работает, на впс пердит пять минут и отваливается со стековерфлоу, надо дебажить (знаю примерно где обосрался).
#3TN9TQ
(0)
/ @mugiseyebrows / 2111 дней назад

Практический смысл моего (на самом деле не моего) язычка я вижу в рендере красивых одностраничных пдфов с рамочками и всем таким (инб4 возьми фантомжс и не еби мозг), но пока с пдфом я не хочу возиться и рендерю в картинку, но прицел на абстракцию контекста взят и впринципе можно рендерить хоть в окна на экране, хоть в текстуры опенгла, хоть сериализовать команды в жсон и отправлять в браузер рисовать по канвасу (милениал изобетает иксы).
Что я и реализовал для будущего веб-фидла
https://mugiseyebrows.github.io/img/mugiml19.png
https://mugiseyebrows.github.io/mugiml/hflex6.html
#H6ORSM
(9)
/ @mugiseyebrows / 2111 дней назад
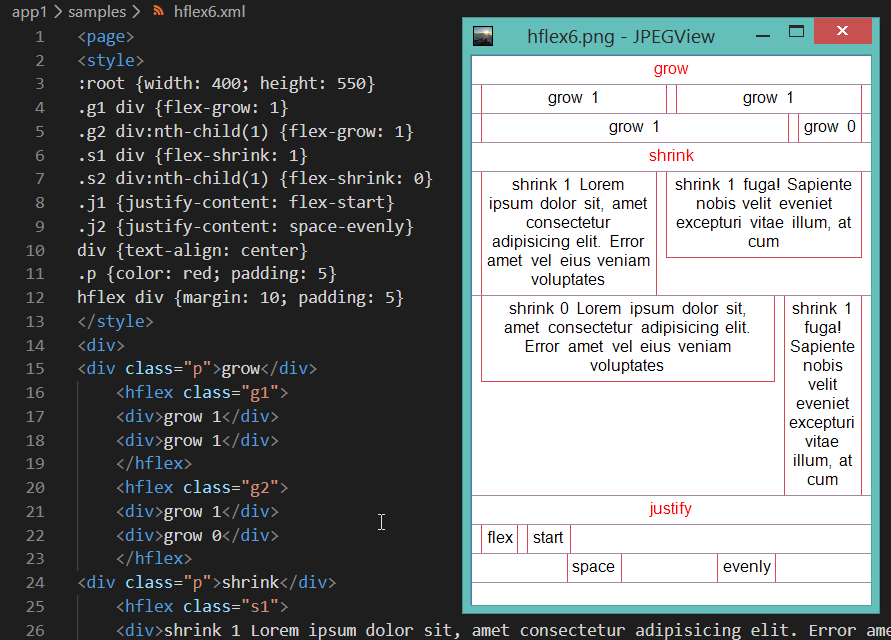
Горизонтальные флексы флексят
https://mugiseyebrows.github.io/img/mugiml18.png
#94IOXT
(2)
/ @mugiseyebrows / 2112 дней назад
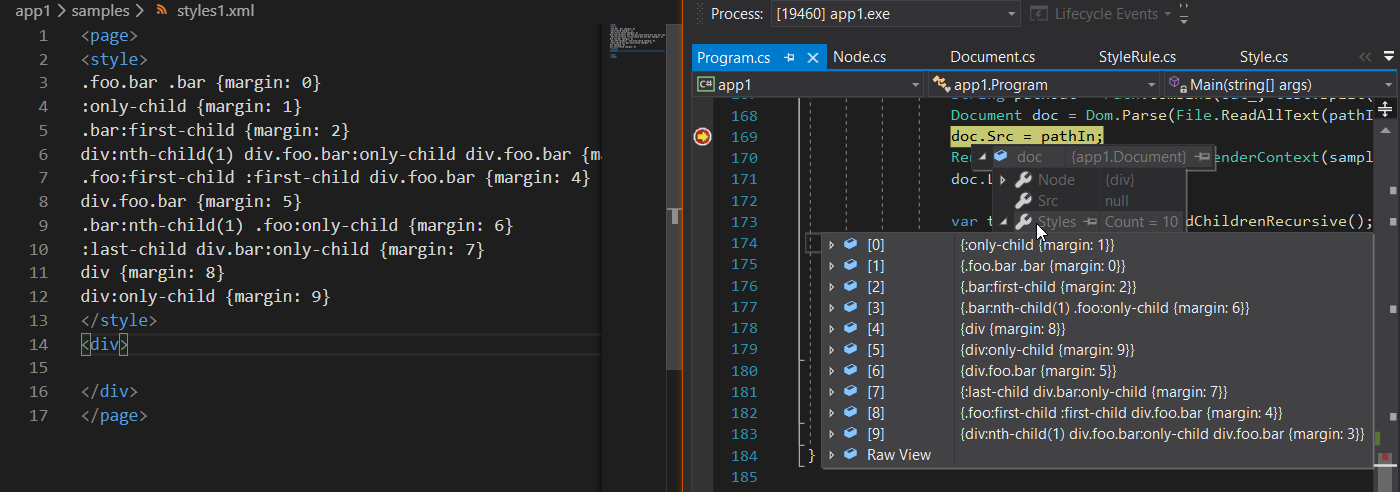
Сегодня я сделал сортировочку css стилей чтобы они в правильном порядке применялись и коменты в них
https://mugiseyebrows.github.io/img/mugiml17.png
а ещё потренькал моно и сконпелял хелоуворлд на впсочке (хочется веб-демку запилить) (но лень в бубунту перегружаться), `xbuild` не понимает мой `csproj`, просто `mcs` не могу потому что зависимости мозги ебут, `string.Split(char[] , StringSplitOptions)` не доложили, короч буду докер кочать (на десктоп) со всем добром чтобы не ебаться (всё равно придётся ебаться)
#ZO3C3N
(1)
/ @mugiseyebrows / 2113 дней назад
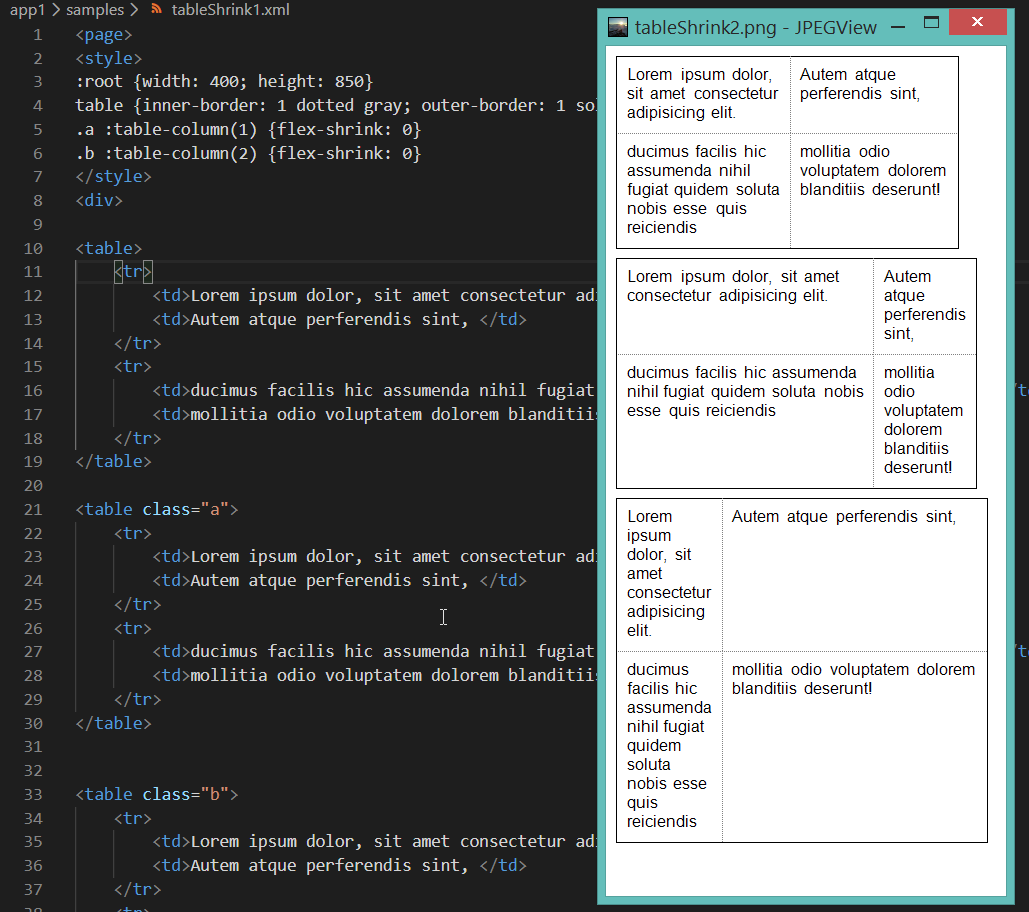
Таблички ресайзятся под давлением размеров контейнера уважая flex-shrink (насколько это возможно)
https://mugiseyebrows.github.io/img/mugiml16.png
#ZRPQSW
(5)
/ @mugiseyebrows / 2114 дней назад

Цоперайт © 2010-2016 @stiletto.